In contrast to the majority of posts on the project blog, I want to focus on the technical side of things. In particular, I want to highlight a few ways that we at the Zooniverse have changed our public offerings and internal practices based on lessons learned during our multi-year collaboration as part of the Davy Notebooks Project (henceforth DNP).
One of the biggest impacts of this collaboration has been increased opportunities for teams aiming to build image-based text transcription projects that feature a common type of data organization. In most cases, a team’s dataset will be made up of multiple sub-groups of images. These sub-groups are typically uploaded via the Project Builder as different subject sets. For a project with multiple subject sets, teams need to possess enough information about the content and structure of their images across these sub-groupings to know whether they can all be sent to the same workflow, or whether they require different classification methods.
Sometimes the content of the subject sets will merit varied technical approaches – e.g. a subject set containing tabular data will require different tools for data collection than a subject set containing letters – but other times a single technical approach can be applied to all sub-groupings for an entire dataset. The DNP is an example of the latter. Their full set of images is subdivided into individual, physical notebooks, all with the same goal of text transcription (composed of an underline marking + collaborative transcription) and a series of follow-up questions about what the participant has just transcribed.
For cases like this on the Zooniverse platform, the traditional technical approach would be to create a single workflow and associate all of the subject sets with that workflow, either simultaneously or in a staggered approach (e.g. activating a new subject set once the previous has been retired). However, over the past several years we have seen that, for archival materials in particular, it is beneficial to expose some of the organizational structure behind a dataset, to give participants access to more information about the sub-groupings and options about how they want to participate.
What I mean by ‘exposing structure’ here is providing information about: 1) how the full dataset is organized; 2) what – if any – the relationship is between subjects in a given set (e.g. if they should be displayed to participants in a certain order); and 3) which materials will be available for transcription and when. Additionally, if teams can provide options for volunteers (i.e. make multiple subject sets available simultaneously) that then gives greater agency to participants by allowing them to choose what they want to work on.
However, the setup process for this approach had some issues. For project teams, it was frustrating to have to build a new workflow for every single subject set, particularly if they were re-creating a complex workflow. Teams were also having to keep workflows set to ‘active’ even after the subject set was fully retired, to ensure that they continued to appear on the Stats page (to provide a record of how much collective effort participants had put into the project over time).
For our Zooniverse team, it meant additional work, too: if a workflow had advanced or experimental features requiring our help, those would all need to be set up manually as well. The DNP workflows use the Transcription Task, which requires Zooniverse-side configuration in order for collaborative transcription to work properly. If the configuration isn’t exactly right (e.g. if there are typos or the right box isn’t ticked), it can impact how the task appears on the project frontend.
After the re-launch of the DNP in 2021, we realized we could build support systems for this process into the platform, reducing the risk of error and saving time for both ourselves and for research teams using the Project Builder.
First, we added a Copy Workflow button to the Project Builder ‘Workflows’ page.

Fig. 1: The Copy Workflow button
This allows teams to duplicate a workflow simply by pressing the ‘Copy’ button and giving the workflow a new name. Later iterations of this button ensured that advanced and administrative settings were also copied.
Second, Zooniverse backend developer Michelle Yuen wrote an automated configuration script for workflows using the Transcription Task. Instead of manually inputting the configuration via a user interface, we can simply run the Python script on a command line interface (such as Mac Terminal) to set up a given workflow. This reduces the risk of human error during setup, and is also much, much faster.
Third, to bring additional context to the data being presented, we made it easier internally for our team to set up projects that allow participants to classify images in a particular sequence. In the case of the DNP, images are served in the order they appear within a given notebook, instead of at random (which is the default behavior on the Zooniverse platform). If this sequential classification setting is turned on for a given workflow, it will remain ‘On’ when that workflow is copied.
Although the features described above made it much easier to set up projects using this approach, and to contextualize subjects within a given set, there were still some technical complications caused by creating a lot of workflows on a single project. For example, project teams still needed to rely on the Zooniverse team to create a new workflow, so we wondered if there was a way to make this process more independent.
As part of the Engaging Crowds project, we built an indexing tool that would display the contents of subject sets and allow project participants to choose individual subjects to work on. For part of this effort, we took inspiration from the DNP and created infrastructure that allows participants to choose a subject set to work on within a given workflow.
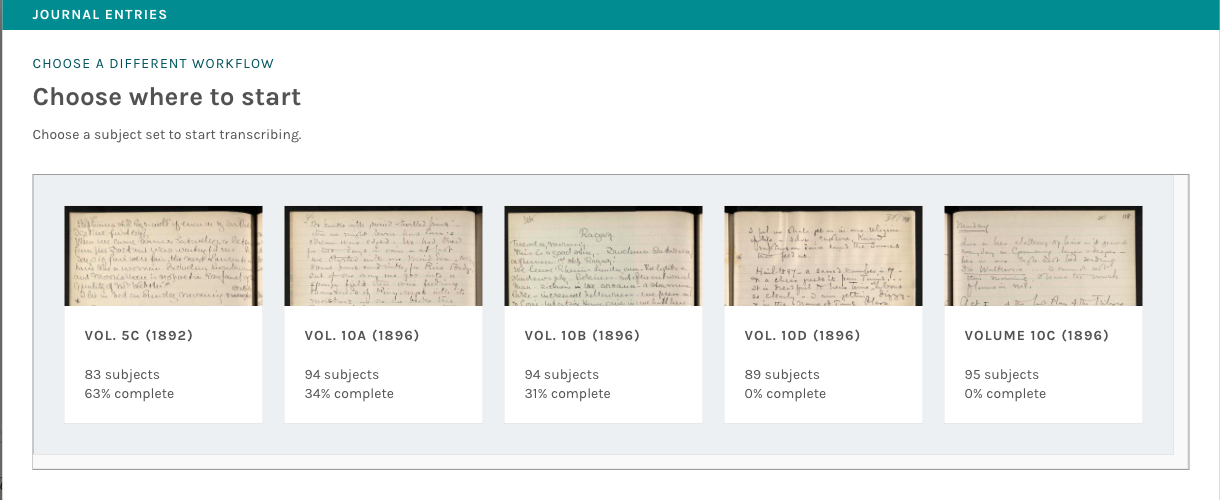
Fig. 2: A screenshot from the Poets & Lovers project, showing the subject set selection modal (click to enlarge)
Project teams using this feature can add multiple subject sets to a single workflow, and participants will then be prompted to choose which one they want to work on. This means that teams only need to set up a single workflow and add their subject sets as needed, but the data in those subject sets will remain separate from the other subject sets.
As shown in the screenshots above, the selection modal also shows completeness statistics, including when a subject set is finished and no longer requires additional classification.
These changes to the technical infrastructure may seem small, but they have already been very impactful for project teams, the Zooniverse team, and participants. I think the lessons we’ve learned from the DNP are great examples of how paying attention to feedback and user experience can lead to positive outcomes for technical collaborators as well as project teams and participants alike.