The first of a series of blogs presenting wide-ranging perspectives on The Ruskin’s collection from academics and curators nationally and internationally.
In this post, Chris Donaldson, Lecturer in Cultural History at Lancaster University, and James Maclaine, Senior Curator, Fish at the Natural History Museum, discuss their view of a connection between a drawing in The Ruskin Whitehouse Collection and a ‘type specimen’ in the collections of the Natural History Museum.
Studying the past can be a bit like pulling threads. The more you pull, the more you can unravel. In this case, the first thread is one of John Ruskin’s drawings.
Ruskin (1819–1900) was a polymath. He’s often thought of as a writer, artist and critic. He’s known for championing Turner’s paintings, and for writing about medieval architecture. Tourists in Venice still carry abridged copies of his books today.
But Ruskin was more than all that as well. He was also passionate about the natural world. The drawing we’re referring to reflects that. It isn’t a picture of the Rialto, after all. It’s a drawing of a rather extraordinary fish.

This drawing is part of The Ruskin’s collection. (You can view the catalogue entry for it here.) It has been displayed at Lancaster University around a half dozen times over the past 20 years. But until recently, little has been known about the provenance of the drawing. What little is known about it is based on the inscription in its lower righthand corner: ‘(Brit Museum) J Ruskin’.
Ruskin loved the British Museum. He spent many happy hours there pouring over books and sketching objects. Most of the items Ruskin sketched at the museum were antiquities. But it seems likely that he drew this fish there, too. Britain’s national natural history collection wasn’t moved to its current home (now the Natural History Museum) until the 1880s.
Ruskin didn’t date his drawing, and he didn’t include any notes about the fish. What species was it? Where did it come from? How large was it? The drawing doesn’t tell us, and we’re left wondering what it was about the fish that reeled Ruskin in.
A few years ago, Stephen Wildman suggested that the fish might have reminded Ruskin of ‘the peculiar large-headed fish in the foreground of Turner’s painting The Slave Ship’, now in the Museum of Fine Arts, Boston.[1] That’s a compelling conjecture. Ruskin once owned Turner’s painting, and he studied it extensively. But this insight doesn’t help us narrow in on a likely date.
Riffling through Ruskin’s papers, however, does shine a little light. On Friday, 16 December 1870, Ruskin jotted in his diary that he’d spent the previous day ‘in [the] British museum’, where he ‘drew [a] beetle-browed fish.’[2] Evidently, the fish’s bulging forehead was part of what caught his eye.
That fish has a tale of its own, of course, and that tale is the second thread in this story. The ‘beetle-browed fish’ Ruskin drew was a prowfish that was plucked from the waters of West Australia around 180 years ago. Dried and stuffed, the fish became the first specimen of its species documented by Europeans. George Grey, the governor of South Australia, gave it to the British Museum in the early 1840s.
John Richardson, the naturalist and explorer, first classified the fish in 1844. He dubbed the species Pataecus fronto. The name attests to Richardson’s classical education. Pataeci was the Roman rendering of the name the Phoenicians used to describe the dwarfish figures (or pittuchim) carved on the prows of their ships. Fronto, for its part, means ‘beetle-browed’.

The name is apt. Pataecus fronto is a relatively small fish, and it has a protruding forehead. What’s more, its dorsal fin looks a bit like a Native American headdress, and that helps explain the species’ other, more problematic, common name, the ‘Red Indianfish’.
Like Richardson’s description, the name ‘Red Indianfish’ is a reflection of the European gaze. Both names evince a Western view of the fish’s appearance, and they reveal how the natural wonders of the world were translated into colonial knowledge.
Both names treat the fish as an exotic object, not an organism. They don’t account for its habitat or behaviour. Nor for that matter do they account for the way it was perceived by Australia’s indigenous peoples. The species’ Aboriginal name isn’t, to our knowledge, recorded.
Today, the specimen Richardson catalogued is part of the collections of the Natural History Museum (catalogue number BMNH 1844.9.3.11), and it still serves as the definitive example (or ‘type specimen’) of its species. This is clearly the fish Ruskin drew back in 1870.
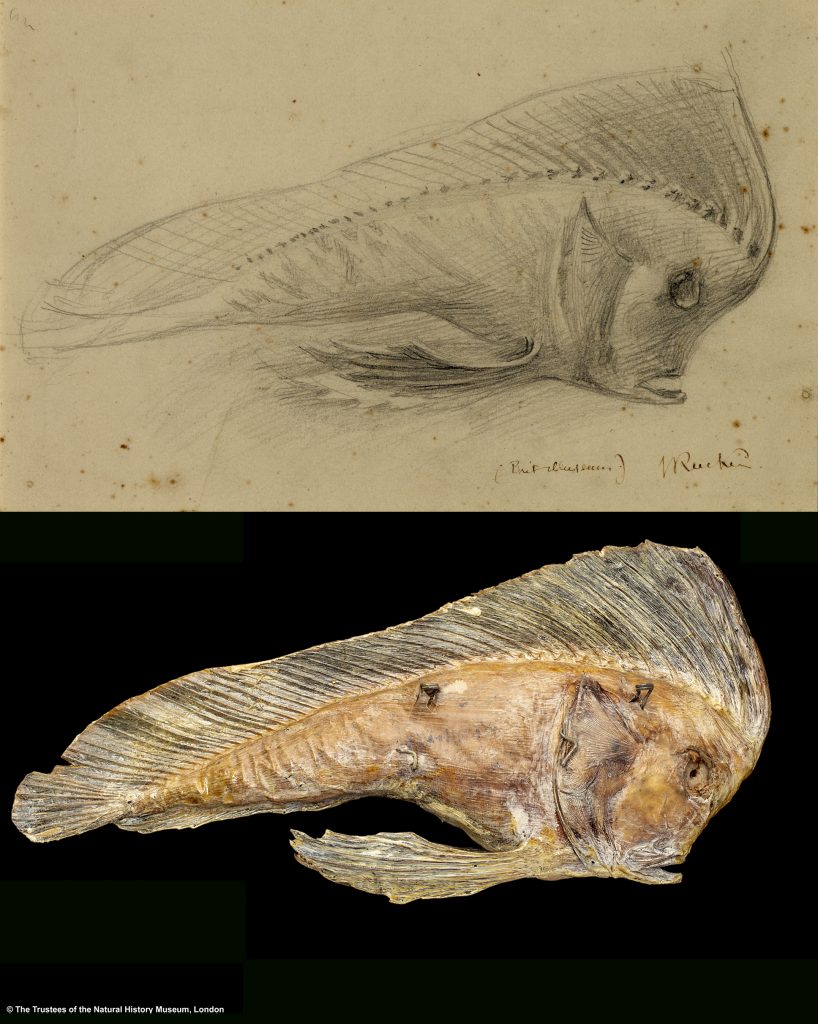
Having drawn out the separate threads of their stories, it’s striking to bring images of these two items together. So much else has changed or vanished over the past 150 odd years. Yet, the two of them have survived.
But what does re-uniting them allow us to see? It certainly helps to answer a few factual questions and to flesh out each item’s history. But is that all?
The answer is ‘no’, of course. Bringing the two items together raises questions we wouldn’t have otherwise asked. For starters, looking at the two items side by side prompts critical reflection on Ruskin’s drawing.
Does the drawing repeat or critique the colonial logic inherent in the fish’s classification? Is it significant that Ruskin chose to depict the fish without naming it or noting its size or origin? Does it matter that he decided not to draw the hooks affixed to the fish? Does his drawing reduce the fish to a mere object? Or does the drawing suggest a different kind of curiosity?
It’s worth noting here that Ruskin didn’t consider drawing to be a mere form of amusement. It was a way of training the eye to see. He argued that ‘the excellence of an artist […] depends wholly on refinement of perception’.[3] So, perhaps the way he drew this fish reflects his interest in it as a pure organic form.
Such an interest might be seen to ignore the colonial history embodied in the fish as a specimen. Consequently, the drawing might be dismissed as an example of the Victorian fascination with curiosities and the exotic.
But then, too, the interest expressed through Ruskin’s drawing might be seen in other ways. The drawing might be seen to hold the colonial knowledge accrued about the specimen in abeyance. In doing so, it might be seen to return us to the fish itself, inviting us to behold it with wonder, anew.
These aren’t questions we propose to answer on our own. They’re questions that connecting collections allow us to explore with others, and we would welcome hearing your thoughts.
Notes
[1] Stephen Wildman, Life Distilled: Ruskin and Still Life (Lancaster: Lancaster University, 2016), p. 21.
[2] John Ruskin, MS16, fol. 58, The Ruskin – Library, Museum and Research Centre, Lancaster University; and Joan Evans and John Howard Whitehouse, The Diaries of John Ruskin (Oxford: Clarendon Press, 1958), vol. 2, p. 708.
[3] John Ruskin, The Elements of Drawing (London: Smith, Elder & Co., 1857), p. xi (Library Edition, vol. 15, p. 12).
Biographical note
Chris Donaldson is Lecturer in Cultural History at Lancaster University and a Research Fellow at The Ruskin – Library, Museum and Research Centre.
James Maclaine is Senior Curator, Fish, in the Vertebrates Division, Life Sciences Department of the Natural History Museum.
Acknowledgement
We’d like to thank Sally Keith and her colleagues in the Lancaster Environment Centre for their input and suggestions.