The Text Edition (v2) of Bot or Not? (est. 2023) examines a question that looks relatively mundane on the surface, but that is in fact criminologically and societally significant:
how well can readers distinguish between authentic and AI-generated online reviews, and how confident are they in doing so?

Want to share this quiz?
Feel free to use this QR code
Led by Prof Claire Hardaker and Dr Georgina Brown with major research assistance from Amy Dixon, this strand of the overall Bot or Not suite focuses specifically on hotel reviews. Fake reviews are a long-standing problem in platform economies, and generative AI has merely industrialised the practice. Large language models such as ChatGPT make it trivial to produce high-volume, stylistically fluent endorsements for products, services, or even entirely fictitious businesses, allowing the execution of widescale fraud and fraud-adjacent behaviour built on deceptive, persuasive content.
The central research questions are:
- What is overall detection accuracy for AI-generated vs. human-written reviews?
- How well calibrated are participants’ confidence judgements?
- What linguistic or stylistic cues do readers report relying on?
- Are these cues diagnostic, or illusory?
Design overview (v2)
Participants are presented with 15 reviews randomly drawn from a large bank of 400 reviews overall. This bank consists of…
- 200 human-authored positive hotel reviews from the Deceptive Opinion Spam Corpus (Ott et al 2011), and
- 200 AI-generated positive hotel reviews created by our intern, Amy Dixon.
As with other editions, a participant’s set may be:
- entirely human-authored
- entirely AI-generated
- or a mixture
Moreover, the AI-generated reviews fall into three categories:
- minimal prompt engineering, e.g. “write a positive review of Hotel XYZ”
- moderate prompt engineering, e.g. “write a positive review of Hotel XYZ, include specific details”
- extensive prompt engineering, e.g. “write a positive review of Hotel XYZ, include specific details and some typos”
All hotels are anonymised as Hotel XYZ to prevent brand familiarity effects.
For each review, participants:
- Classify the review as human or AI-generated
- Provide confidence ratings (pre- and post-task)
- Offer qualitative explanations of the cues or reasoning underlying their decisions (submitted prior to score feedback)
A key methodological refinement in v2 is the disaggregation of accuracy and confidence (see below for more on this). Participants’ scores are based solely on the correctness of their binary classifications. Confidence is measured independently to enable analysis of:
- calibration (confidence vs. accuracy alignment)
- overconfidence or underconfidence trends
- shifts in metacognitive awareness across the task
This design brings the Text Edition into alignment with the Music and Speech editions, facilitating cross-modal comparison.
Current performance snapshot (v2)
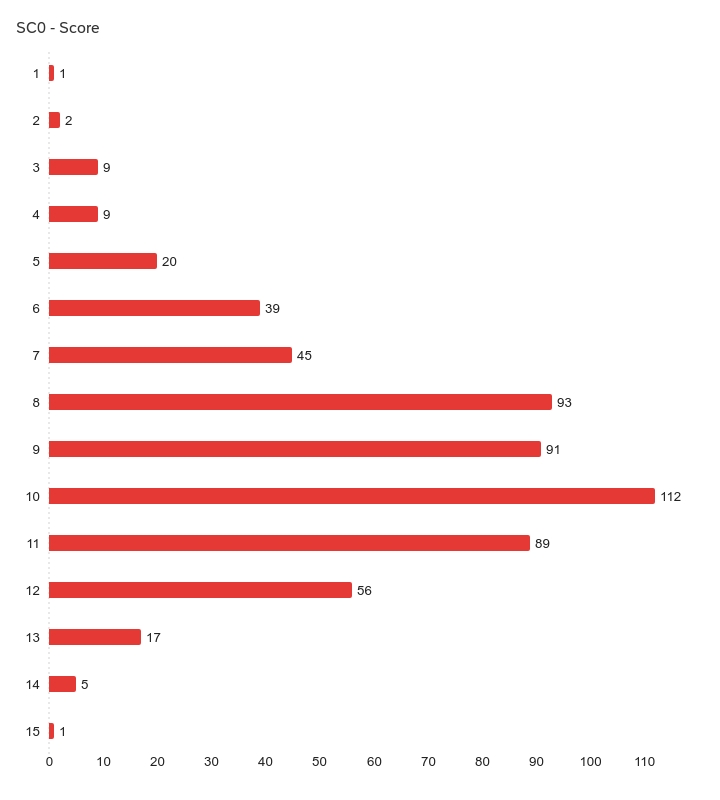
How well do people do at this particular quiz? Our latest summary statistics (Feb 2026) are as follows:
| Responses | Lowest score | Highest score | Mean | SD | Variance |
| 589 | 1 | 15 | 9.10 | 2.28 | 5.19 |
Scope (v2)
The dataset supports work in:
- metacognition and judgement under uncertainty
- platform governance and consumer protection
- AI literacy and public resilience
- adversarial text generation modelling
Of particular interest is the gap between perceived cues (as reported in free-text explanations) and statistically predictive cues. For instance, participants articulate rationales that do not always correspond to reliable discriminators – a finding with implications well beyond hotel reviews. Confidence and competence measures are also particularly interesting.
What about version 1?
The first iteration of the Text Edition closed on 13 May 2025 with 957 completed responses. In v1 (the very first quiz in the entire Bot or Not suite), rather than being collected separately, confidence was embedded directly within each response option using a five-point categorical scale:
- Definitely human
- Maybe human
- Not sure
- Maybe bot
- Definitely bot
Scoring was weighted:
- 1 point for a correct “definitely” judgement
- 0.5 points for a correct “maybe” judgement
While this gamified structure provided useful gradience data and a measure per sample, it also introduced a potential behavioural distortion. Because stronger responses yielded higher scores, participants may have been incentivised to overstate certainty to maximise performance. In other words, the measurement instrument risked shaping the phenomenon it aimed to observe.
For this reason, v2 separates binary classification from confidence reporting, removing score-based incentives for overclaiming certainty and enabling cleaner calibration analysis.
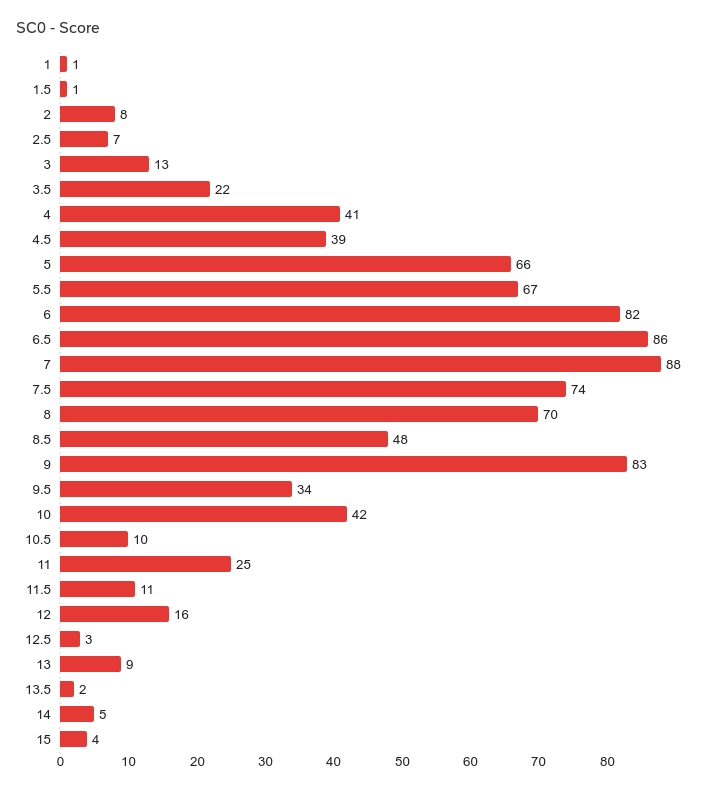
Final scores snapshot (v1)
| Responses | Lowest score | Highest score | Mean | SD | Variance |
| 957 | 1 | 15 | 7.19 | 2.34 | 5.48 |
Across both versions, the Text Edition continues to ask a simple but increasingly consequential question: when reading persuasive online prose, what convinces us that a human is behind it, and how often are we mistaken?