The Music Edition (v1) of Bot or Not? (est. 2025) forms part of an ESRC-supported programme of research led by Prof Claire Hardaker, Dr Georgina Brown, and Hope McVean at Lancaster University. It examines a deceptively simple question:
how accurately can listeners distinguish between AI-generated and human singing voices, and what cues inform those judgements?

Want to share this quiz?
Feel free to use this QR code
While synthetic speech has now reached extremely high levels of perceptual plausibility, singing presents a more complex test case. It combines pitch stability, vibrato, breath control, phrasing, timbral nuance, stylistic convention, and emotional projection – all of which may function as perceptual signals of “humanness”. The project investigates whether these signals remain diagnostic as generative models improve, or if they are also gradually being removed from our AI-detection toolkit.
The wider relevance is non-trivial. If AI-generated vocals become reliably indistinguishable from human performance, the implications extend across:
- performer identity and attribution
- copyright and neighbouring rights
- fraud and impersonation risks
- creative labour markets
- export and regulatory frameworks
Public controversies – such as the The Velvet Sundown case – illustrate how quickly questions of authorship, authenticity, and disclosure become socially and legally charged.
Design overview
The Music Edition draws from a curated larger bank of both human-created and AI-generated songs. Each participant is randomly presented with nine samples, which may comprise any combination (all human, all AI, or mixed). For each sample, participants:
- Classify the voice as human or AI-generated
- Provide confidence ratings (pre- and post-task)
- Offer qualitative explanations of the cues or reasoning underlying their decisions (submitted prior to score feedback)
This structure enables analysis at multiple levels:
- Overall detection accuracy
- Calibration of confidence vs. performance
- Metacognitive shift (change in confidence across exposure)
- Cue salience (via thematic and corpus-linguistic analysis of explanations)
- Error patterns across voice types, genres, or production styles
Importantly, participants are instructed to focus on the voice only. Instrumentation may be synthetic in both human- and AI-voiced tracks, and human performances may legitimately include processing effects (e.g., pitch correction). The experimental question is not whether production sounds modern, but whether vocal origin is perceptually identifiable.
Current performance snapshot
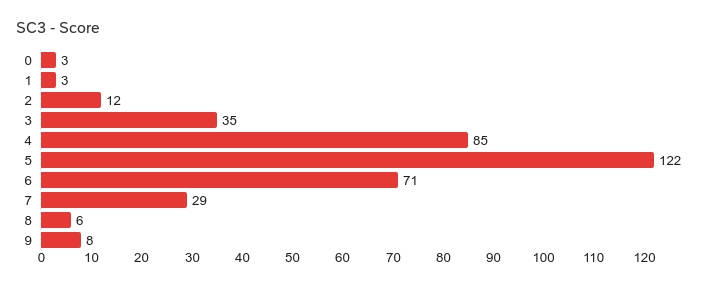
How well do people do at this particular quiz? Our latest summary statistics (Feb 2026) are as follows:
| Responses | Lowest score | Highest score | Mean | SD | Variance |
| 374 | 0 | 9 | 4.90 | 1.48 | 2.20 |
Data and collaboration
The dataset comprises perceptual judgements, confidence metrics, and free-text reasoning data linked to known ground truth labels. The project is designed to support:
- perceptual and cognitive research on synthetic media
- linguistic analysis of AI vocal production
- human-AI discrimination modelling
- regulatory and policy-oriented research
- risk assessment in an array of contexts
At its core, the Music Edition asks a simple question with increasingly complex consequences: when we hear singing, what makes us believe there is a person behind it, and when are we wrong? It also takes us into deeply philosophical questions around the nature of being and identity: must an artist really exist for the associated art to be perceived as legitimate?
We believe that the answers to these questions are no longer merely aesthetic. They are becoming both existential and evidential.