The Speech Edition (v2) of Bot or Not? (est. 2024) investigates a question with clear security, forensic, and societal implications:
how accurately can listeners distinguish between human and AI-generated speech — and how well calibrated is their confidence?

Want to share this quiz?
Feel free to use this QR code
Led by Prof Claire Hardaker, Dr Georgina Brown, and Hope McVean, this Edition examines perceptual discrimination in the context of rapidly advancing voice synthesis. Synthetic speech systems now produce highly naturalistic prosody, intonation, and timbre. While this technology has legitimate applications, it is also routinely exploited in fraud, defamation, impersonation, disinformation, and harassment contexts. The evidential stakes are therefore considerably higher than mere curiosity.
Design overview (v2)
Participants are presented with 15 speech samples of around 3-5 seconds in length (longer, we would note, than the phrase “My voice is my password”) which have been randomly drawn from a larger curated bank of 400 recordings. This bank is created from:
- 200 authentic human speech samples
- 200 AI-generated speech samples
All materials are drawn from ASVspoof 2019, a widely used benchmark dataset in automatic speaker verification and anti-spoofing research. This allows the perceptual findings to sit alongside computational work conducted internationally.
Just as the Text and Music Editions have varying quality levels in the AI-generated content, so too does the Speech Edition. Samples are striated across both voice quality (how good we felt they were, ranging from very poor/obvious AI voices through to extremely convincing, human-like voices) and recording quality (phone quality, internet quality, studio quality):
|
Line Quality Voice quality |
Phone
(poor) |
Internet
(medium) |
Studio
(excellent) |
Total
|
| Poor | 22 | 22 | 23 | 67 |
| Medium | 22 | 23 | 22 | 67 |
| Excellent | 23 | 22 | 22 | 67 |
| Total | 67 | 67 | 67 | 201 |
This is to test whether, for instance, a poor quality line such as a phone recording may mask more artefacts of AI generated speech versus a studio quality recording which may only allow the most convincing instances of AI generated language to pass as human.
As with other editions, any given participant may receive all human samples, all AI samples, or a mixture. For each sample, participants:
- Make a binary judgement (human or bot)
- Provide confidence ratings (pre- and post-test)
- Submit a free-text explanation describing the cues or reasoning underlying their decision (before receiving their score).
This structure enables analysis of:
- overall detection accuracy
- human vs. AI hit rates
- confidence calibration
- metacognitive shifts across the task
- reported cue salience versus statistically predictive features
As with the other tests, separating classification from confidence allows cleaner modelling of judgement under uncertainty.
Current performance snapshot (v2)
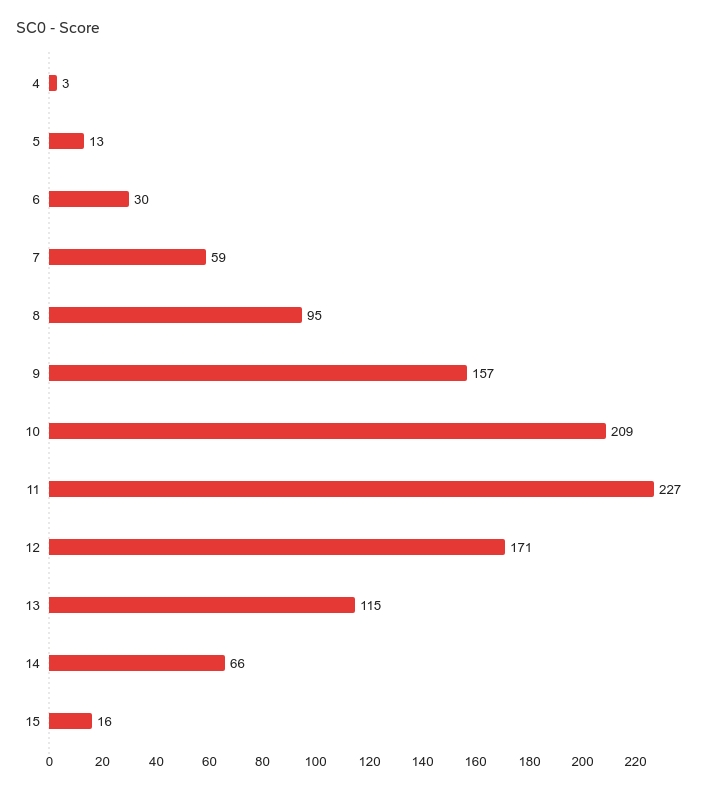
How well do people do at this particular quiz? Our latest summary statistics (Feb 2026) are as follows:
| Responses | Lowest score | Highest score | Mean | SD | Variance |
| 1,161 | 4 | 15 | 10.46 | 2.10 | 4.43 |
Analytical scope
The Speech Edition (v2) supports work in:
- forensic phonetics and speaker comparison
- deception and impersonation detection
- human-AI perceptual modelling
- risk assessment in fraud and social engineering
- public resilience to synthetic media
Of particular interest is the mismatch – frequently observed in related work – between the cues listeners believe are diagnostic (e.g., “accents”, “flat intonation”, “breaths/breathing”, “odd pacing”) and those that empirically predict correct classification. Understanding this gap is essential if training, regulation, or technical safeguards are to be evidence-based rather than intuition-driven.
What about version 1?
The initial Speech Edition (v1) was swiftly implemented for a short notice event as a modest little online form comprising 12 speech samples. You can even still play it here. Participants received a score at the end, but this version didn’t collect:
- confidence measures
- qualitative explanations
- scores
Although several hundred individuals completed the task and we learned a lot from being present whilst people undertook the quiz, the absence of stored response data limited its research utility. The simplicity of the instrument was a win for our needs in that moment, but we quickly missed the methodological depth. For these reasons, the project was redeveloped into the current Qualtrics-based v2, massively expanding the stimulus bank, capturing richer response data, and aligning the Speech Edition methodologically with the Text and Music editions.
(But we do love a scrappy quick fix, which is why we’ve never had the heart to take it down.)